
What is the meaning of OCR in scanning and PDF terminology? What does “scan to OCR mean”? How does optical character recognition work? Why would you need to know about OCR technology?
Definition of Optical Character Recognition and How It’s Used in Scanning Technology
Optical character recognition, or OCR, is a useful piece of technology that detects text within scanned documents and images. OCR software is designed to recognize text (and numbers and symbols) in an image and convert it into editable text within an electronic document. The original image could be a digital file, such as JPG, TIFF or other commonly used image formats. OCRs are also useful for scanned PDFs, which we’ll explain.
You may be wondering, why would you want a picture to be converted into text? Well, a picture can be a lot of things. You can take a picture of handwritten notes, a plaque at a museum, or even a physical document, and then use an OCR to convert it to a digital, editable document — typically into a PDF.
Why are some PDFs immediately editable using a PDF editable? That’s because these are native PDFs, which are different from scanned PDFs.
- Native PDF: Native PDFs are created using a digital document editor (Microsoft Word, for example) and whose text fields are editable and able to be copied. A native PDF also could be a file that had been converted from another format, such as DOC, XLS or PPT.
- Scanned PDF: A PDF created by scanning a document is, basically, a photo of a document. All the elements in the PDF are a single image. The text in a scanned PDF isn’t editable or searchable without the use of OCR technology.
How Can I Use an OCR on My Documents?
If you have a scanned document or a picture that you’ve converted to a PDF, you’ll need to use a PDF OCR to detect and extract the text from the picture and convert it to an editable format.
PDF.Live offers two options for this: A manual OCR tool and an automatic OCR.
Manual OCR
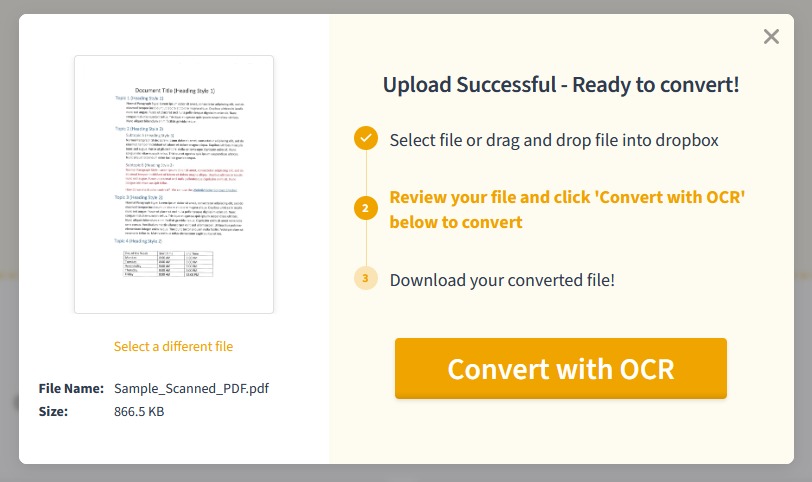
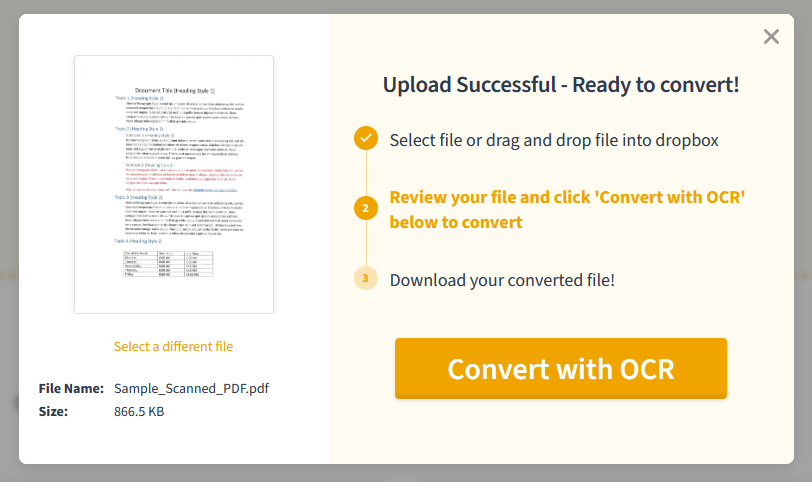
PDF.Live’s manual OCR tool works by having you drag and drop your PDF into the tool.Then you review your file and convert it with an OCR. This may take a few minutes, depending on the size of the document and the density of the text.
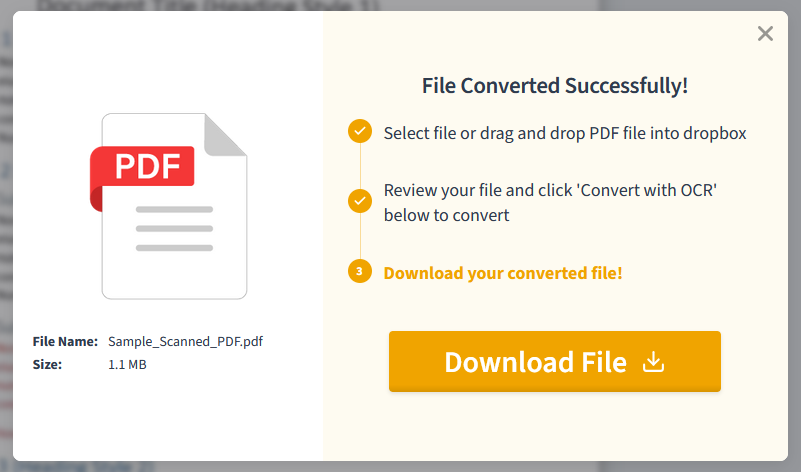
By default, your OCR converted file will be downloaded as a PDF. It may not look any different to you, but to a PDF editor, the text within will now be editable!
After you’ve converted your PDF with the OCR, PDF.Live gives you a few options for managing the new PDF. For example, you can select Edit PDF to begin editing the text within the new PDF.
The results of the OCR will depend on the quality of the scanned PDF, so if you want a document that’s easier to edit, we recommend immediately converting the document to a DOC using our PDF to DOC converter.
Automatic OCR
PDF.Live offers the following converters:
All these PDF converters employ an automatic OCR that detects if the PDF that you’re uploading has text in an image format. During the conversion process, PDF.Live will automatically engage the OCR to convert the text to an editable format.
If your PDF conversion takes a couple of minutes, this is probably because the OCR has been engaged.
Once your PDF is converted, the text in any images you have should be fully editable in the new format. If you’re finding that the text isn’t editable or are having trouble converting your PDF to another format, this is most likely related to the quality of the scanned document.
Try to get a clearer or cleaner scan of the document so our OCR can accurately detect the text. You may need to increase the resolution or size of the scan. You can also try adjusting the position of the document so it’s straighter when you scan it. OCRs may be less effective with converting handwritten notes.
How Does an OCR Work?
OCRs may range in specific functions, but they generally work the same way: You import an image file into the OCR. Then, the OCR program locates and recognizes characters such as English letters, numbers, and symbols (e.g. !#^&), and exports the text it finds into a new document. Some advanced OCRs will even try to find and export the size and formatting settings of the text in the image.
OCRs also have pattern recognition to detect commonalities in the text that it’s scanning. The letter “K” for example, may look one way when I write it but an entirely different way when you write it. But an OCR can detect patterns in the letters we write to determine what the letter is. Let’s say we both write this sentence:
“Lucky Luke likes lakes.”
If you took an image of that sentence and imported it into an OCR, the OCR will notice that the letter K is used 4 times in this sentence. You probably wrote that letter the same way all 4 times and will continue to write it that way in the rest of the document that the OCR is scanning. The OCR will also use this sentence to determine how you write the letter “L,” “l,” and more. OCRs cross-reference letters across different instances to make a more accurate digital version of an image.
The success rate, or how accurate the text is to the original document, of an OCR will be determined by the quality of the image you import. If your image isn’t taken on a good camera or is low-resolution, the OCR may struggle to produce an accurate document.
OCRs are used a lot in the real world. Some apps on your phone can take pictures of physical notes you made and convert them to digital text. The U.S. Postal Service uses OCRs to read letter addresses and sort mail more effectively.
Why Use Optical Character Recognition?
OCRs are particularly useful when you want to edit and interact with a piece of text more effectively. If you have physical notes, you can’t use the CTRL + F to search for specific words or phrases. If you made a mistake in your notes or need to add something new, it’s much easier to make a change in a digital document than a physical one.
OCRs are also useful if you receive a piece of text that’s difficult to read. An OCR can scan that piece of text and convert it into a digital document that’s much easier to read. You can then increase the font size of that text to make it even more decipherable.
While the PDF file format isn’t necessarily an “image,” it also isn’t an editable doc. PDFs are designed to maintain their formatting settings across any device to be easy to read and access no matter what. If you want to edit the text in a PDF, however, you’ll either need to use a PDF reader or convert the PDF to an editable doc. If you choose the latter option, PDF.Live’s automated OCR scans the PDF and creates a new document with the text from the original PDF that you can then edit.
PDF.Live offers all options:
- An OCR to make the text in your PDFs editable.
- A PDF editor entirely in your browser (no downloads required!) that you can use to make small adjustments to your PDF.
- A PDF to Doc converter that converts PDFs to editable docs. You can then open that editable doc in a document editor like Microsoft Word.